Cloud 66 101
Concepts & terminology
What is Cloud 66?
Cloud 66 is a DevOps-automation service that allows you to easily build, deploy and maintain your applications, and their supporting components, on any cloud or server.
Cloud 66 allows you to centralize the provisioning and management of:
- Applications (and app servers)
- Databases
- Load Balancers
- Caches
- Message queues
- File storage
- Firewalls
- SSL certificates
- Monitoring and logging
...as well as all of the configuration files, settings and environment variables on which these components rely.
How does this differ from other PaaS providers?
Unlike traditional PaaS offerings like Heroku or Google App Engine, Cloud 66 allows you to use your own servers - whether in the cloud, in a data center or even on your own premises. We support both public and private clouds, as well as hybrids and bare metal installations.
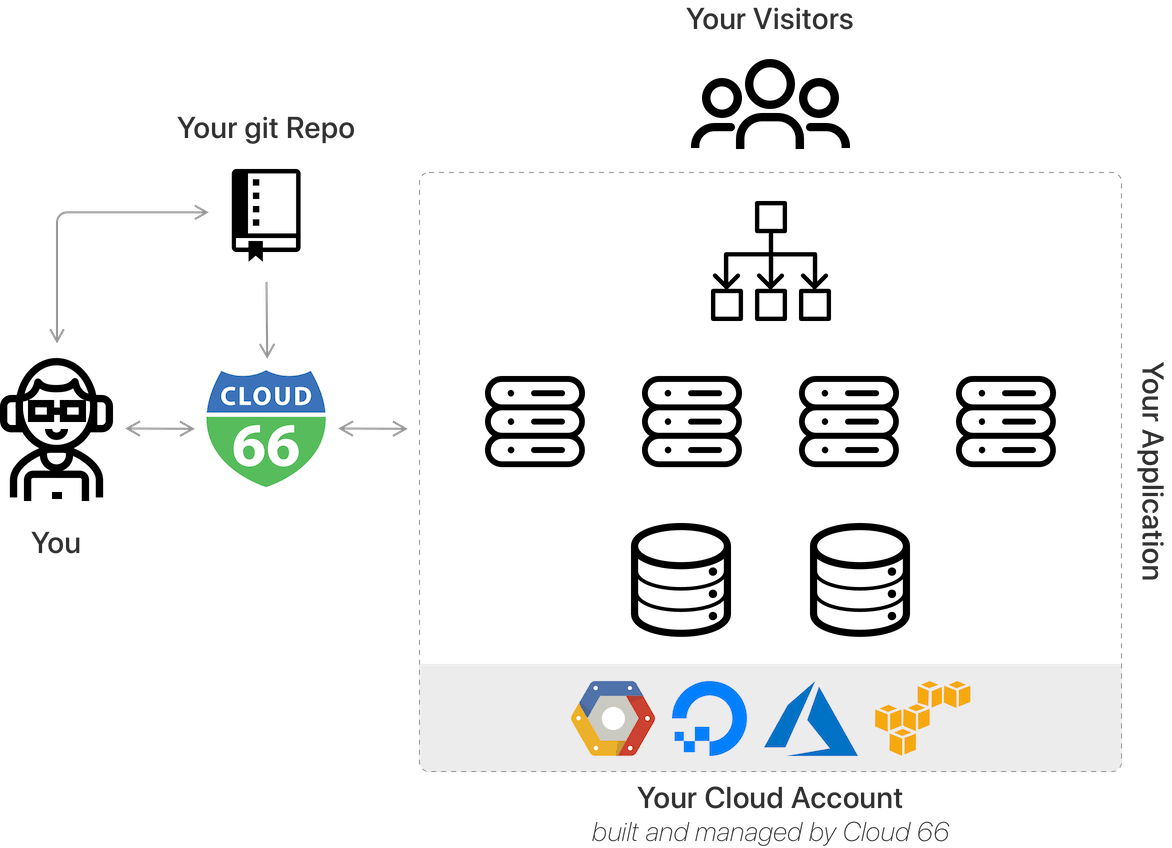
Cloud 66 is primarily developer-focused. It automates and standardizes the important but repetitive (and error-prone) tasks involved in configuring and deploying code to infrastructure. The platform is designed to work for both small teams without dedicated DevOps resources, and larger organizations with separate DevOps teams.
Application vs stack
In previous versions of Cloud 66, and this documentation, we used the concept of a “stack” to describe much the same concept as we now describe using “application”. The two concepts are related but not identical.
In particular “stack” tends to include both underlying infrastructure and the components running on that substrate, whereas “application” is more abstracted from the underlying infrastructure.
However, when reading any documentation or our forums, it will often be helpful to think of “stack” and “application” as effectively synonymous.
In a general sense, both these terms encapsulate the same thing: an interconnected collection of components, configurations and services that are presented to the world as a single, coherent piece of software.
The principle of immutability
At Cloud 66 we believe in the principle that application components should be treated as immutable whenever possible. This means that, if a configuration change is required, it is always preferable to build a new version of that component from scratch, and swap it with an existing component than to manually modify the configuration of that component.
That's why we focus our efforts on making the building and deploying of components as quick, reliable and automated as possible. If spinning up a new version of an existing component takes ten minutes, why bother trying to fiddle with configurations, or upgrade in place - actions that could easily break your application?
Automation and repeatability
Whether upgrading, building from scratch or scaling horizontally, we focus on making the roll-out of components as automated, consistent and repeatable as possible. We have many features that support this, including:
- The Manifest file captures settings for infrastructural components in a simple YAML format, making it quick and easy to roll out additional instances of a component without any manual intervention
- CustomConfig gives you a powerful, version-controlled interface for customizing the configuration files for components like databases and Nginx
- Deploy Hooks allow you to automate the customization of components during your build and deployment process - for example installing a custom package, or a series of packages that depend on one another.
Load balancing
Cloud 66 supports several levels and methods of balancing the load on an application:
- External load balancing via cloud services / providers
- Load balancing across your application’s own hosts via Nginx or HAproxy
- Load balancing across the containers and Pods running within the application via Kubernetes
All of these methods share the same goal - ensuring that your application is able to cope with the influx of users and traffic without degrading in performance or running out of resources completely.
This documentation addresses the configuration of cloud-based load balancers, Nginx and HAproxy, but there are dozens of other platforms and methods that can help you manage the load on your application.
If you are interested in learning more about this subject, Matt Klein has written an excellent introduction to load balancing.
Proxies and SSL / TLS termination
Both Nginx and HAproxy can be set up to handle SSL / TLS termination - in other words, they act as the public face of an application and provide a route to your SSL certificates. This saves you from having to set up multiple instances of your certificates throughout your infrastructure and allows for more advanced load balancing features like X-Forwarded HTTP headers (XFF).
What is StackScore?
StackScore™ is a score that provides an indication of how reliable, resilient and performant your application is when deployed on your servers. It consists of five key metrics that are graded from A to F, and the overall StackScore is the lowest of the scores across these five metrics.
- Code: Ensures your code does not have security issues by checking for known vulnerabilities.
- Backups and data integrity: This tracks whether or not you are backing up your databases (with managed and/or unmanaged backups), and whether or not you verify your backups.
- Connectivity: Checks whether or not you are sharing your front-end and back-end on the same server. This is affected by how much memory you have on your servers, among other factors.
- Performance: Checks if you have a load balancer, as well as different server configuration metrics.
- Security: Tracks your firewall settings for potential security issues.
Suggestion
Always try to keep your stacks at an A StackScore™ level to ensure application health.
Cloud 66 constantly seeks to update and improve the StackScore algorithm to consider new data points as well as external conditions, which means that your StackScore will change over time.